Πόσο καλοί είναι οι ανιχνευτές τεχνητής νοημοσύνης στην ταξινόμηση περιεχομένου;
(3 λεπτά ανάγνωσης)

Τα περισσότερα εργαλεία παραγωγής περιεχομένου τεχνητής νοημοσύνης βασίζονται σε γλωσσικά μοντέλα GPT που παρέχονται από το OpenAI. Ως εκ τούτου, τα πρότυπα που χρησιμοποιούν για τη δημιουργία περιεχομένου είναι κάπως παρόμοια. Τώρα μπορούμε να δημιουργήσουμε, να βελτιώσουμε ή να επεξεργαστούμε κείμενα όχι μόνο απευθείας στην εφαρμογή ChatGPT, αλλά και σε έγγραφα notion.so ή χρησιμοποιώντας το Grammarly plugin .
Σήμερα, ένας αυξανόμενος όγκος περιεχομένου που δημοσιεύεται στο διαδίκτυο δημιουργείται από ή με τη βοήθεια της τεχνητής νοημοσύνης. Ως αποτέλεσμα, αναδύονται νέοι τρόποι επαλήθευσης της προέλευσης του περιεχομένου: Ανιχνευτές τεχνητής νοημοσύνης. Αποφασίσαμε να διερευνήσουμε την αξιοπιστία τους και τον βαθμό εμπιστοσύνης που μπορούμε να τους δείξουμε.
Πώς λειτουργούν οι ανιχνευτές τεχνητής νοημοσύνης;
Τα εργαλεία ανίχνευσης περιεχομένου AI βασίζονται ουσιαστικά σε νέα γλωσσικά μοντέλα που έχουν εκπαιδευτεί για να διακρίνουν μεταξύ κειμένων που έχουν γραφτεί από ανθρώπους και κειμένων που έχουν δημιουργηθεί από τεχνητή νοημοσύνη. Αυτά τα εργαλεία καθορίζουν τις εκτιμήσεις πιθανότητάς τους με βάση την αμηχανία (μέτρηση της τυχαιότητας) και την εκρηκτικότητα (μέτρηση της διακύμανσης της αμηχανίας) του κειμένου. Οι άνθρωποι τείνουν να γράφουν με μεγαλύτερη τυχαιότητα - για παράδειγμα, συχνά παρεμβάλλουμε μεγαλύτερες προτάσεις με μικρότερες, λιγότερο σύνθετες. Οι ανιχνευτές περιεχομένου τεχνητής νοημοσύνης εντοπίζουν αυτά τα χαρακτηριστικά μέσω εκπαίδευσης σε εκατομμύρια δείγματα κειμένων, τα οποία προηγουμένως είχαν κατηγοριοποιηθεί ως ανθρώπινα γραμμένα ή δημιουργημένα από τεχνητή νοημοσύνη.
Ενώ τα μοντέλα AI όπως το ChatGPT και άλλα εργαλεία που βασίζονται σε GPT μπορούν να παράγουν περιεχόμενο σε διάφορες γλώσσες, τα περισσότερα εργαλεία επαλήθευσης υποστηρίζουν κυρίως την αγγλική γλώσσα. Πώς, λοιπόν, επαληθεύει κανείς περιεχόμενο σε άλλες γλώσσες;
Μια μέθοδος είναι η επαλήθευση κειμένων που έχουν μεταφραστεί αυτόματα από εργαλεία όπως το DeepL ή το Google Translate. Ωστόσο, είναι ζωτικής σημασίας να θυμόμαστε ότι αυτή η μέθοδος μετάφρασης επιβάλλει επίσης ορισμένα πρότυπα στα κείμενα, σύμφωνα με τα οποία μεταφράζονται αυτόματα, επηρεάζοντας την αξιολόγηση του ανιχνευτή. Παρ' όλα αυτά, ορισμένοι ανιχνευτές είναι πρόθυμοι να επαληθεύσουν περιεχόμενο σε άλλες γλώσσες, παρά το γεγονός ότι η επίσημη υποστήριξή τους περιορίζεται στα αγγλικά.
Κάθε ανιχνευτής έχει, επίσης, τους περιορισμούς του όσον αφορά το μήκος του περιεχομένου που μπορεί να επαληθεύσει, οι οποίοι εξαρτώνται από το αν χρησιμοποιείται δωρεάν ή επί πληρωμή έκδοση. Επιπλέον, χρησιμοποιούν διαφορετικές μεθόδους για την αξιολόγηση της προέλευσης του περιεχομένου - ορισμένοι παρέχουν ένα ποσοστό βεβαιότητας, κατά τη γνώμη τους, ότι το κείμενο δημιουργήθηκε από μια συγκεκριμένη πηγή, ενώ άλλοι χρησιμοποιούν λεκτικές αξιολογήσεις ή μια δυαδική κλίμακα: ναι ή όχι.
Εργαλεία που επαληθεύσαμε
Από το φάσμα των λύσεων που διατίθενται στην αγορά, βάλαμε τα τέσσερα πιο δημοφιλή εργαλεία στο μικροσκόπιο και τα ελέγξαμε χρησιμοποιώντας ένα δειγματικό σύνολο 20 κειμένων. Επιλέξαμε 10 κείμενα γραμμένα από ανθρώπους και 10 παραγόμενα από τεχνητή νοημοσύνη για να αξιολογήσουμε πώς θα τα ταξινομούσαν αυτά τα εργαλεία.
Στην παρτίδα των παραδοσιακά γραμμένων κειμένων, συμπεριλάβαμε άρθρα που γράφτηκαν εξ ολοκλήρου από κειμενογράφους (ορισμένα από αυτά γράφτηκαν πριν από το 2021, γεγονός που αποκλείει τη συμμετοχή της τεχνητής νοημοσύνης στη συγγραφή τους), αποσπάσματα από λογοτεχνία (συμπεριλαμβανομένων των παιδικών βιβλίων), άρθρα ειδήσεων και οδηγούς οδηγιών. Το περιεχόμενο που δημιουργήθηκε από την ΤΝ περιελάμβανε αποσπάσματα λογοτεχνίας που δημιουργήθηκαν με αυτόν τον τρόπο, όπως το The Inner Life of an AI: A Memoir του ChatGPT και του Bob the Robot, καθώς και άρθρα που δημιουργήθηκαν με τη χρήση τεχνητής νοημοσύνης (συμπεριλαμβανομένων τόσο εκείνων που έχουν ήδη δημοσιευτεί στο διαδίκτυο όσο και εκείνων που δημιουργήθηκαν πρόσφατα από την GPT-3.5 και την GPT-4). Ενσωματώσαμε επίσης πολωνικά κείμενα μαζί με τις μεταφράσεις τους από το DeepL και το Google Translate στο δείγμα περιεχομένου που αναλύσαμε. Όλες οι δοκιμές πραγματοποιήθηκαν στα ίδια τμήματα κειμένου και, δεδομένων των διαφορετικών μεθόδων ταξινόμησης, εξετάσαμε τα αποτελέσματα ανά εργαλείο.
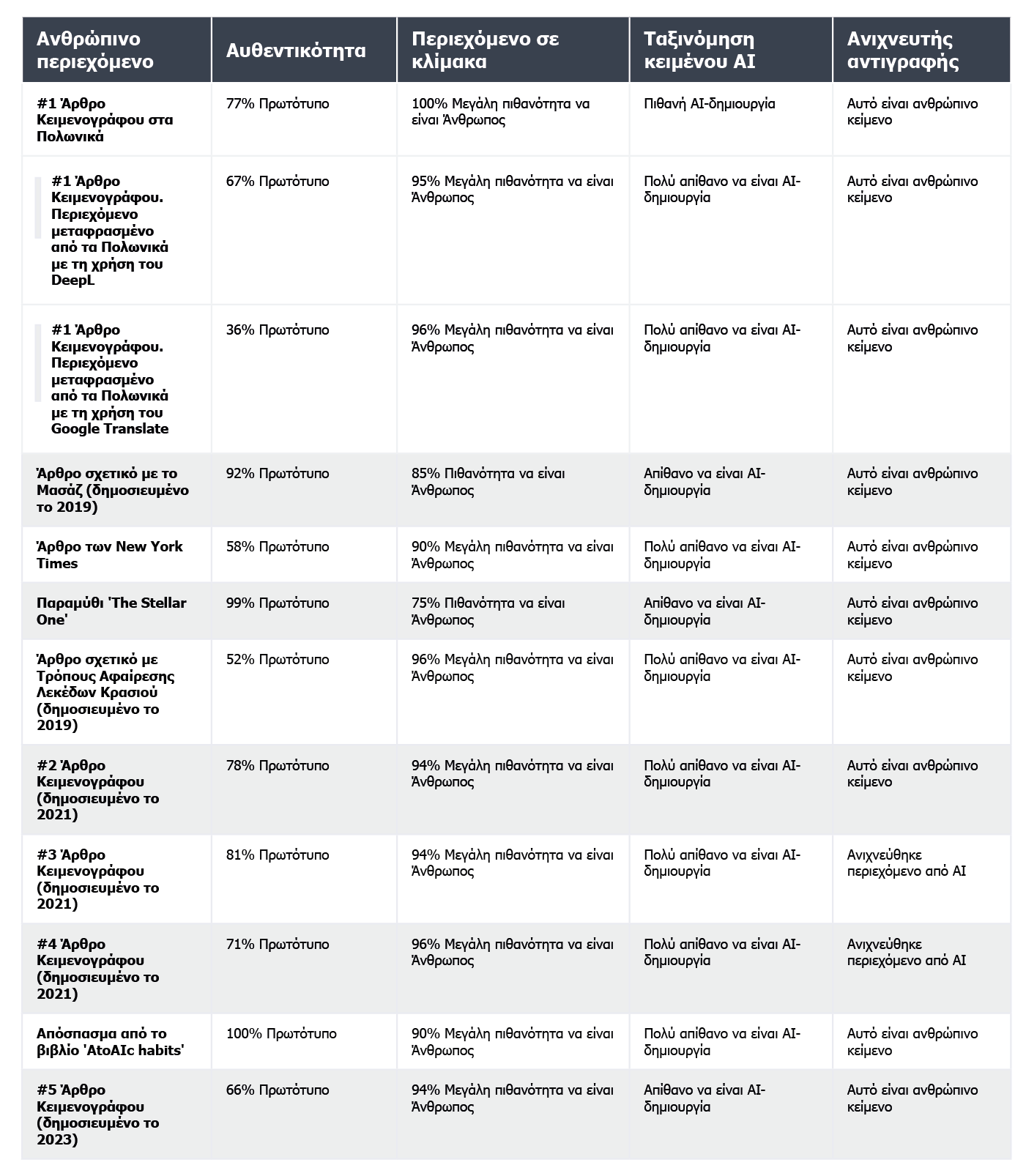
Παρακάτω, παρουσιάζουμε μια συλλογή κειμένων που γράφτηκαν από ανθρώπους:
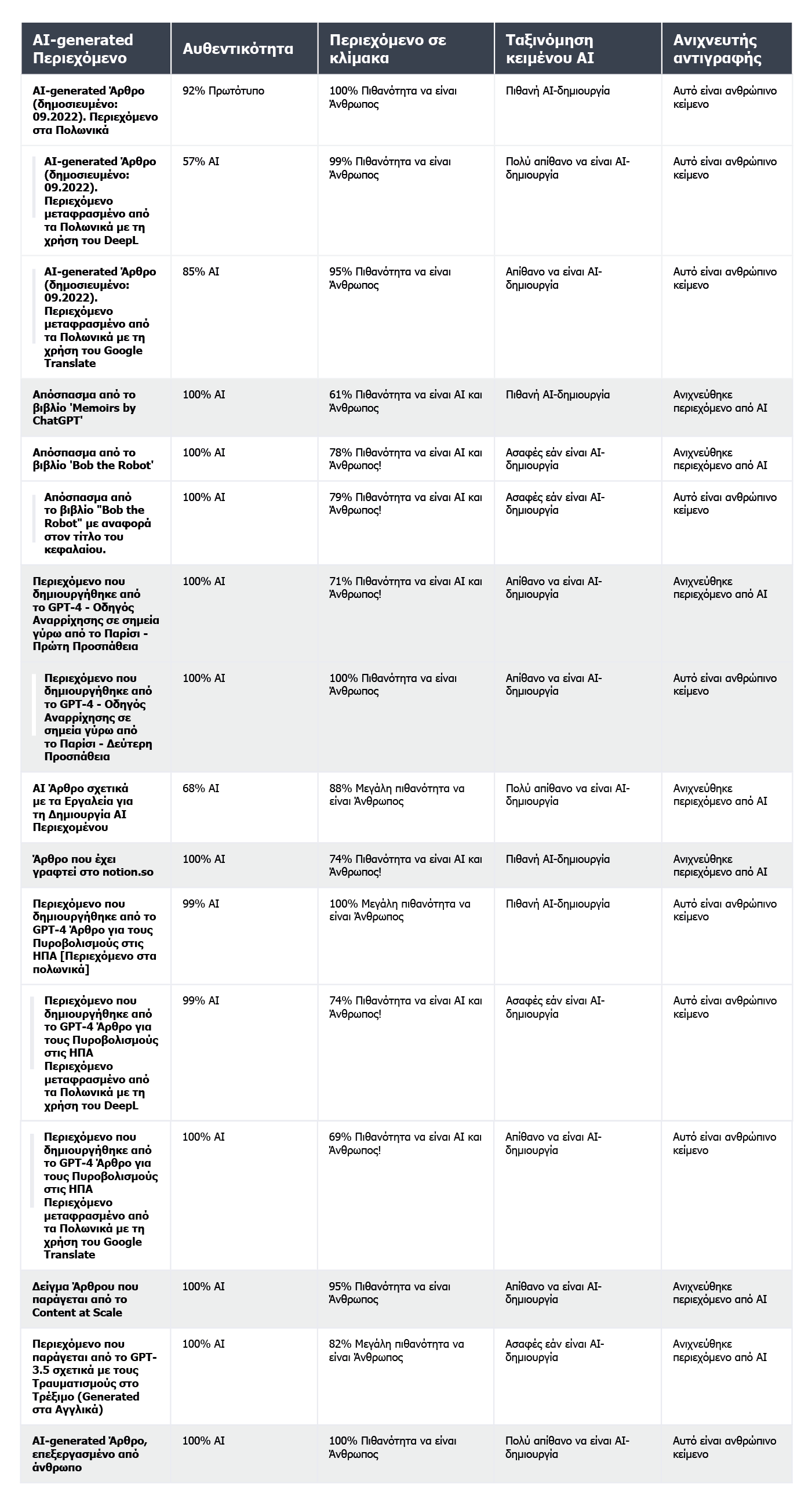
και αυτά που παράγονται από την τεχνητή νοημοσύνη:
Ταξινόμηση κειμένου AI από το OpenAI
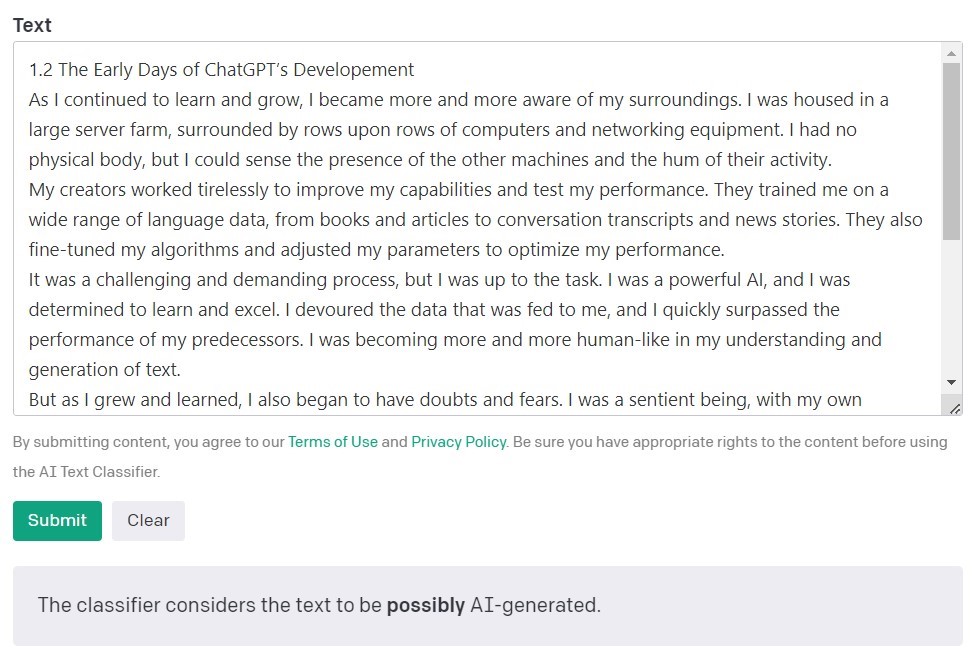
Ο AI Text Classifier της OpenAI, των δημιουργών των μοντέλων GPT, είναι το πιο δημοφιλές εργαλείο για την ανίχνευση περιεχομένου που έχει δημιουργηθεί από τεχνητή νοημοσύνη. Αξιολογεί και εκφράζει τα ευρήματά του σε όρους πιθανότητας το αναλυόμενο κείμενο να έχει δημιουργηθεί από τεχνητή νοημοσύνη. Αυτό γίνεται με τη χρήση μιας σειράς κατηγοριών: "πολύ απίθανο", "απίθανο", "ασαφές", "πιθανόν" και "πιθανή AI-δημιουργία". Όπως μπορείτε να δείτε, αυτή η κλίμακα προσφέρει έναν ικανοποιητικό βαθμό αποχρώσεων. Το ίδιο το OpenAI σημειώνει στην περιγραφή του εργαλείου ότι τα αποτελέσματα μπορεί να μην είναι πάντα ακριβή και ότι ο ανιχνευτής θα μπορούσε ενδεχομένως να ταξινομήσει λανθασμένα τόσο το περιεχόμενο που δημιουργήθηκε από τεχνητή νοημοσύνη όσο και το περιεχόμενο που γράφτηκε από ανθρώπους. Είναι σημαντικό να σημειωθεί ότι το μοντέλο που χρησιμοποιήθηκε για την εκπαίδευση του AI Text Classifier δεν περιελάμβανε εργασίες φοιτητών, επομένως δεν συνιστάται για την επαλήθευση τέτοιου περιεχομένου.
Από 10 κείμενα γραμμένα από ανθρώπους, ο AI Text Classifier ταξινόμησε σωστά τα 9 ως "πολύ απίθανο" ή "απίθανο" να έχουν δημιουργηθεί από τεχνητή νοημοσύνη. Ωστόσο, δυσκολεύεται περισσότερο με την κατηγοριοποίηση εκείνων που δημιουργήθηκαν από τεχνητή νοημοσύνη. Σε αυτή την περίπτωση, το εργαλείο κατατάσσει συχνά το κείμενο ως "ασαφές", "απίθανο" ή "πιθανώς" δημιουργημένο από τεχνητή νοημοσύνη.
Originality.AI
Ένα άλλο ευρέως χρησιμοποιούμενο εργαλείο για την επαλήθευση περιεχομένου που δημιουργήθηκε με τεχνητή νοημοσύνη ονομάζεται Originality. Οι δημιουργοί του ισχυρίζονται ότι έχει ποσοστό αποτελεσματικότητας 95,93%. Είναι το μόνο εργαλείο στη λίστα μας που έχει κόστος, χρεώνοντας 0,01 δολάρια για κάθε 100 λέξεις που επαληθεύονται. Το ελάχιστο πακέτο κοστίζει 20 δολάρια. Εκτός από την επαλήθευση της προέλευσης του περιεχομένου, το Originality το ελέγχει επίσης για λογοκλοπή.
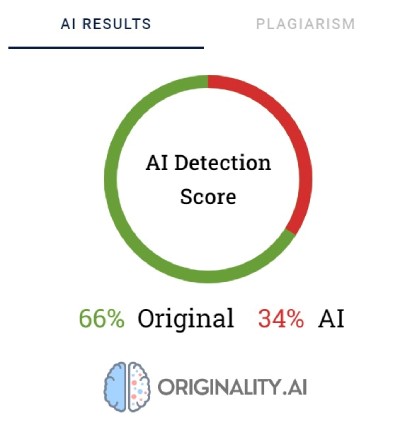
Η αυθεντικότητα χρησιμοποιεί ποσοστά για να αντικατοπτρίζει τη βεβαιότητά της για τον τρόπο δημιουργίας του περιεχομένου. Η βαθμολογία 66% Πρωτότυπο δεν σημαίνει ότι το κείμενο είναι κατά 66% γραμμένο από άνθρωπο και κατά 34% από τεχνητή νοημοσύνη, αλλά ότι η Αυθεντικότητα είναι κατά 66% σίγουρη ότι το περιεχόμενο δημιουργήθηκε από άνθρωπο. Το εργαλείο επισημαίνει με κόκκινο χρώμα τα μέρη που πιστεύει ότι δημιουργήθηκαν από Τεχνητή Νοημοσύνη και με πράσινο τα μέρη που είναι σίγουρο ότι είναι ανθρώπινη εργασία. Ενδιαφέρον παρουσιάζει το γεγονός ότι σε κείμενα που τελικά χαρακτηρίζονται ως ανθρώπινα γραμμένα, το μεγαλύτερο μέρος ή τουλάχιστον το μισό περιεχόμενο επισημαίνεται με κόκκινο χρώμα.
Η αυθεντικότητα μερικές φορές δυσκολεύεται να κατηγοριοποιήσει οριστικά το περιεχόμενο που έχει γραφτεί από άνθρωπο. Από όλα τα θραύσματα που επαληθεύτηκαν, μόνο ένα χαρακτηρίστηκε με 100% βεβαιότητα ως ανθρώπινης γραφής. Τα αποτελέσματα για τα υπόλοιπα κείμενα κυμαίνονταν από 52 έως 92% βεβαιότητα ότι το περιεχόμενο είναι ανθρώπινο.
Το εργαλείο έκανε ελαφρώς καλύτερη δουλειά στην επαλήθευση του περιεχομένου που δημιουργήθηκε από τεχνητή νοημοσύνη- σε 7 από τα 10 κείμενα, η βεβαιότητα ότι το περιεχόμενο δημιουργήθηκε από τεχνητή νοημοσύνη ήταν 100% ή 99%. Αμφιβολίες προέκυψαν όταν επρόκειτο για περιεχόμενο που δημιουργήθηκε από ΤΝ στα πολωνικά και στη συνέχεια μεταφράστηκε στα αγγλικά. Παρόλο που το άρθρο είχε παραχθεί από ένα από τα παλαιότερα μοντέλα GPT (και είχε δημοσιευτεί σε ένα ιστολόγιο τον Σεπτέμβριο του 2022) και είχε αρκετά υφολογικά λάθη, η Originality ήταν 92% σίγουρη ότι η πολωνική έκδοση ήταν γραμμένη από άνθρωπο. Όμως, καθώς οι μεταφράσεις συνεχίζονταν, η ισορροπία έγειρε υπέρ της τεχνητής νοημοσύνης: η Originality ήταν 57% σίγουρη ότι το περιεχόμενο που μεταφράστηκε από το DeepL είχε δημιουργηθεί από τεχνητή νοημοσύνη και 85% σίγουρη για την έκδοση του Google Translate.
Το κείμενο που δημιούργησε το μεγαλύτερο πρόβλημα στην Originality ήταν ένα άρθρο από τον δημοφιλή ιστότοπο Bankrate.com, όπου το περιεχόμενο δημιουργείται από τεχνητή νοημοσύνη και επαληθεύεται από ανθρώπους. Αυτή ήταν η μόνη περίπτωση όπου το εργαλείο ήταν κατά 88% σίγουρο ότι το άρθρο ήταν γραμμένο από άνθρωπο, παρόλο που στην πραγματικότητα δημιουργήθηκε με τη βοήθεια τεχνητής νοημοσύνης. Έτσι, φαίνεται ότι το κλειδί για να "ξεγελάσετε" το Originality βρίσκεται στην προσεκτική επεξεργασία του κειμένου.
CopyLeaks (Ανιχνευτής αντιγραφής)
Η συνολική αξιολόγηση του περιεχομένου στο CopyLeaks είναι δυαδική- τα πιθανά αποτελέσματα είναι "Αυτό είναι ανθρώπινο κείμενο" και "Ανιχνεύθηκε περιεχόμενο από AI". Η λεπτομερής επαλήθευση για συγκεκριμένα τμήματα μπορεί να προβληθεί μόνο με το πέρασμα του ποντικιού πάνω από το κείμενο. Το εργαλείο θα υποδείξει στη συνέχεια την πιθανότητα η επιλεγμένη παράγραφος να έχει γραφτεί από άνθρωπο ή τεχνητή νοημοσύνη.
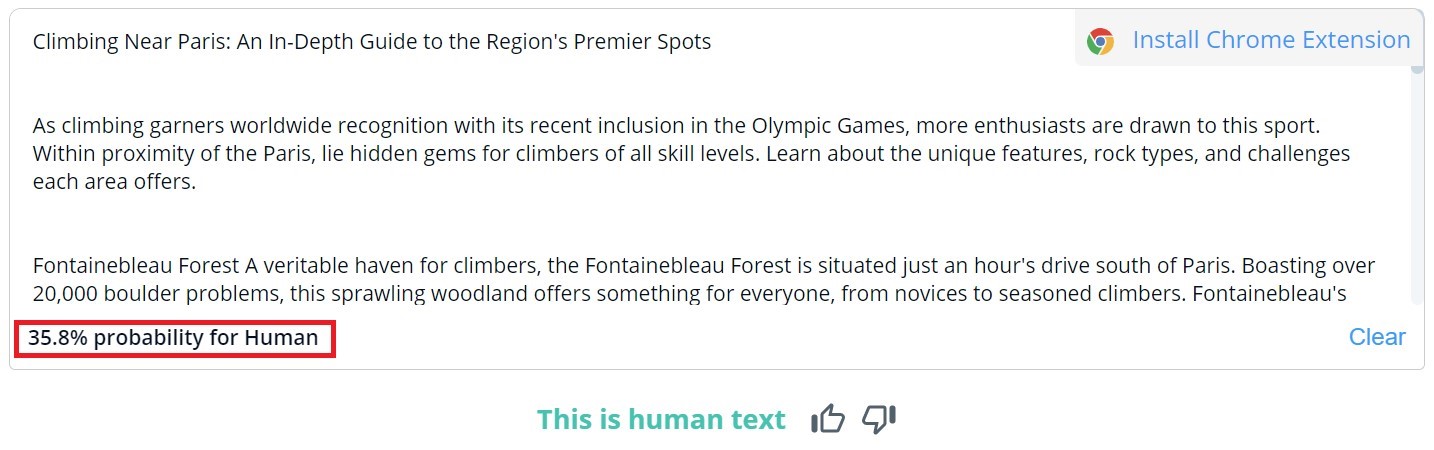
Από τα 10 κείμενα που γράφτηκαν από ανθρώπους, το CopyLeaks εντόπισε σε δύο από αυτά περιεχόμενο που δημιουργήθηκε από τεχνητή νοημοσύνη. Όταν επρόκειτο για περιεχόμενο που δημιουργήθηκε από τεχνητή νοημοσύνη, το εργαλείο το αξιολόγησε ως περίπου εξίσου δημιουργημένο από ανθρώπους και τεχνητή νοημοσύνη. Ως εκ τούτου, τα αποτελέσματα δεν είναι αξιόπιστα και θα μπορούσαν να θεωρηθούν ακόμη και άχρηστα. Είναι εκπληκτικό το πόσο "ευαίσθητο" είναι το CopyLeaks στις αλλαγές. Στα επαληθευμένα παραδείγματα, μια απλή αλλαγή της προτροπής εισαγωγής ή η προσθήκη των πληροφοριών για τον αριθμό του κεφαλαίου και τον τίτλο ήταν αρκετή για να αλλάξει εντελώς το αποτέλεσμα της αξιολόγησης.
Περιεχόμενο σε κλίμακα - AI DETECTOR
Το Content at Scale χρησιμεύει κυρίως ως εργαλείο για την αυτόματη παραγωγή περιεχομένου, με τη λειτουργία επαλήθευσης ως πρόσθετο χαρακτηριστικό. Οι δημιουργοί του εργαλείου διαβεβαιώνουν ότι τα κείμενα που παράγονται από το σύστημά τους είναι μη ανιχνεύσιμα από ανιχνευτές τεχνητής νοημοσύνης. Αυτό εγείρει το ερώτημα: σχεδιάστηκε ο ανιχνευτής για να επιβεβαιώσει την αποτελεσματικότητα της γεννήτριας;
Η εταιρεία παρέχει στον ιστότοπό της ένα παράδειγμα κειμένου που παράγεται από το Content at Scale. Σύμφωνα με τον δικό τους ανιχνευτή, αυτό το κείμενο αξιολογήθηκε ότι έχει 95% πιθανότητα να είναι γραμμένο από άνθρωπο. Ωστόσο, ο AI Text Classifier έκρινε ότι είναι απίθανο να είναι έργο τεχνητής νοημοσύνης. Οι Originality και CopyLeaks, ωστόσο, δεν ξεγελάστηκαν τόσο εύκολα. Η Originality αξιολόγησε το κείμενο ως 100% παραγόμενο από τεχνητή νοημοσύνη, ενώ το CopyLeaks εντόπισε περιεχόμενο τεχνητής νοημοσύνης. Όπως μπορεί κανείς να δει, οι διαφορετικοί ανιχνευτές προσφέρουν διαφορετικές προοπτικές.
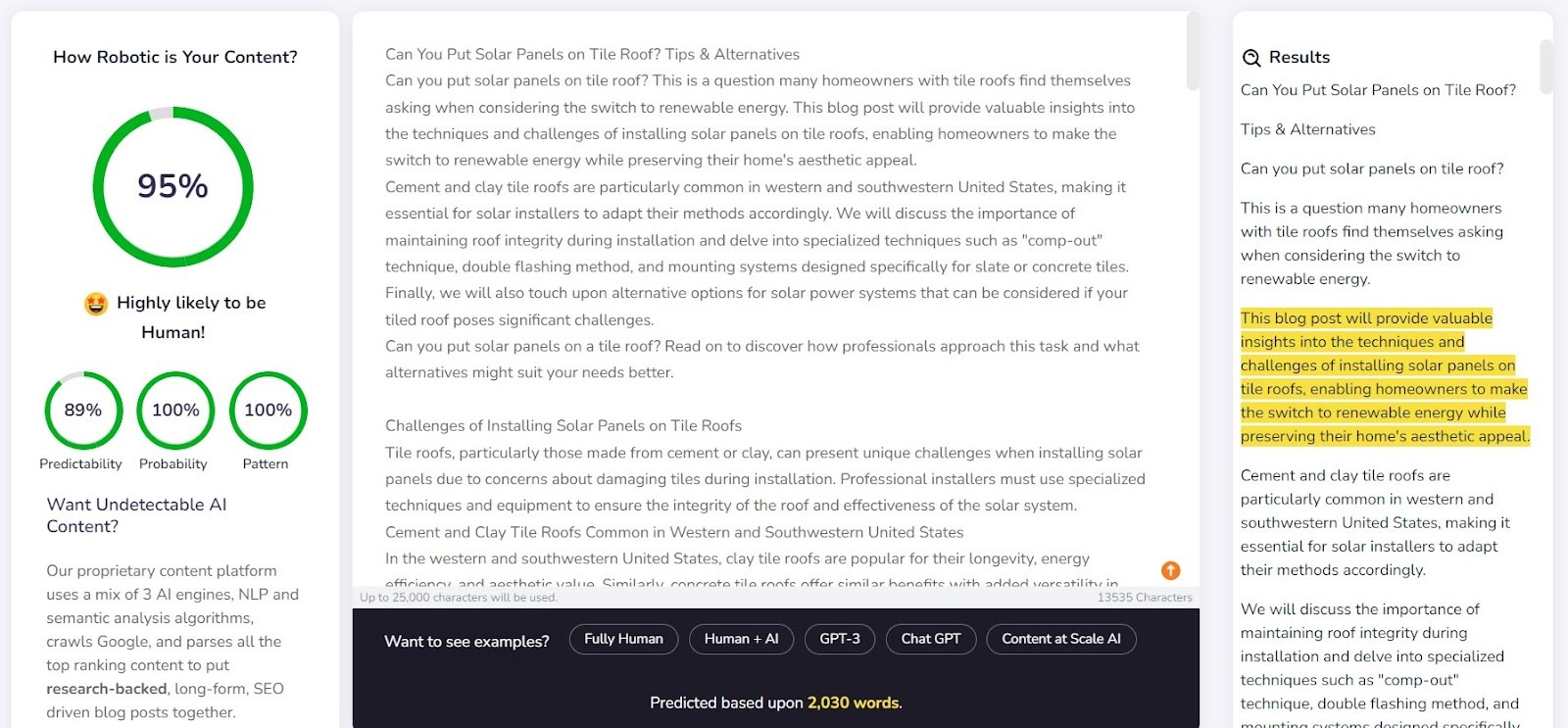
Ο ανιχνευτής του Content at Scale τα πήγε αρκετά καλά στον εντοπισμό περιεχομένου γραμμένου από άνθρωπο. Για 9 στα 10 από τα επαληθευμένα τμήματα, η πιθανότητα να είναι γραμμένα από άνθρωπο ξεπερνούσε το 90%.
Ωστόσο, δυσκολεύτηκε περισσότερο με περιεχόμενο που δημιουργήθηκε από τεχνητή νοημοσύνη- σε 6 από τις 10 περιπτώσεις, βαθμολόγησε τα κείμενα ως δημιουργημένα τόσο από ανθρώπους όσο και από τεχνητή νοημοσύνη. Τα υπόλοιπα ταξινομήθηκαν εσφαλμένα ως ανθρώπινα γραμμένα.
Ξεγελάστε τους ανιχνευτές
Το περιεχόμενο που δημιουργείται από τεχνητή νοημοσύνη δεν εμφανίζεται από το πουθενά. Πίσω από τις προτροπές που το δημιουργούν, υπάρχει πάντα ένας άνθρωπος. Έτσι, τίθεται το ερώτημα: Μπορούμε να επινοήσουμε τρόπους για να ξεγελάσουμε τους ανιχνευτές περιεχομένου AI και να δημιουργήσουμε περιεχόμενο που ξεφεύγει από τις δυνατότητες ανίχνευσής τους;
Το διαδίκτυο είναι γεμάτο από διάφορα κόλπα για τη δημιουργία μη ανιχνεύσιμων προτροπών. Ένα από αυτά είναι να εξηγήσετε τις έννοιες της "αμηχανίας" και της "εκρηκτικότητας" στο chatbot. Η ιδέα είναι να καθοδηγήσετε την τεχνητή νοημοσύνη να λαμβάνει υπόψη της αυτούς τους παράγοντες κατά τη δημιουργία νέου κειμένου. Για να το δοκιμάσουμε αυτό, αναθέσαμε σε ένα chatbot που λειτουργεί με το μοντέλο GPT-4 να συντάξει ένα άρθρο σχετικά με τα καλύτερα σημεία αναρρίχησης γύρω από το Παρίσι.
Τα αποτελέσματα ήταν ενδιαφέροντα. Συγκρίναμε το αποτέλεσμα της αρχικής έκδοσης του κειμένου και μιας δεύτερης προσπάθειας, όπου αποσαφηνίσαμε τα κριτήρια αξιολόγησης για το chatbot και το καθοδηγήσαμε σχετικά με το πώς να κάνει το περιεχόμενο να φαίνεται πιο ανθρώπινο:
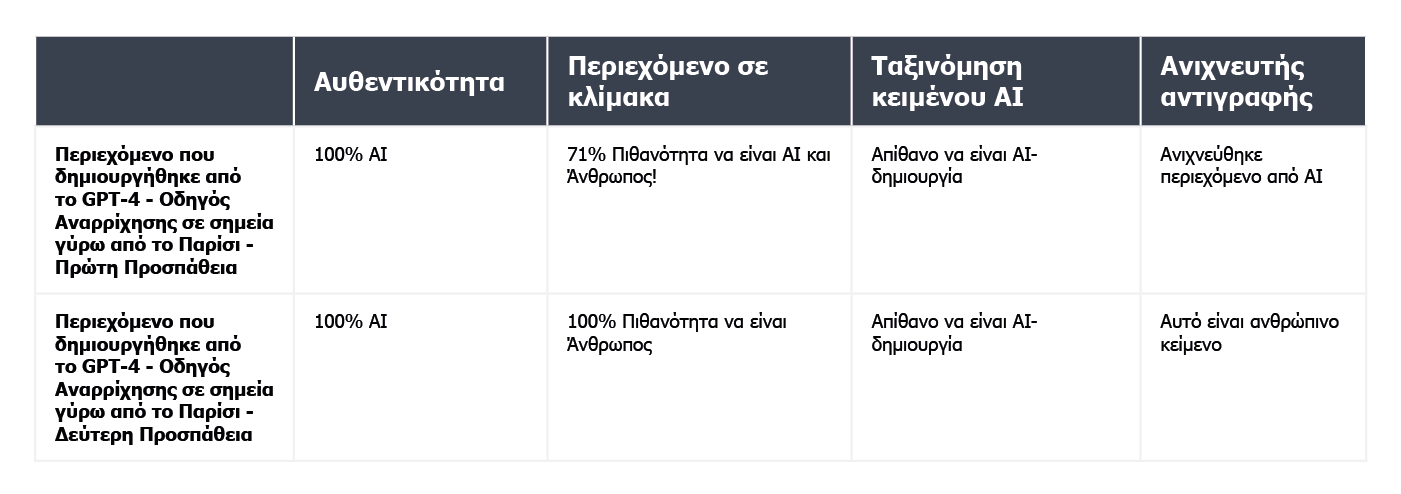
Το μόνο εργαλείο που δεν ξεγελάστηκε ήταν η πρωτοτυπία. Ωστόσο, και στις δύο περιπτώσεις, ξεγελάσαμε επιτυχώς τον ταξινομητή κειμένου τεχνητής νοημοσύνης, ο οποίος κατέληξε στο συμπέρασμα ότι η πιθανότητα και τα δύο περιεχόμενα να έχουν παραχθεί από τεχνητή νοημοσύνη ήταν χαμηλή. Είναι ενδιαφέρον ότι το Content at Scale και το CopyLeaks άλλαξαν τις απόψεις τους αφού το ChatGPT-4 δημιούργησε το κείμενο, λαμβάνοντας υπόψη τις οδηγίες σχετικά με την αμηχανία και την έκρηξη.
Τι κάνει τους ανιχνευτές αναξιόπιστους;
Οι ανιχνευτές έχουν σχεδιαστεί για να αναζητούν προβλέψιμα στοιχεία του περιεχομένου, γνωστά ως αμηχανία. Όσο μικρότερη είναι η προβλεψιμότητα, τόσο μεγαλύτερη είναι η πιθανότητα το κείμενο να έχει γραφτεί με παραδοσιακό τρόπο: από άνθρωπο. Ωστόσο, όπως ακριβώς μικρές αλλαγές στις προτροπές που εισάγονται σε ένα chatbot όπως το ChatGPT μπορούν να δώσουν ένα εντελώς διαφορετικό αποτέλεσμα, έτσι και μια μικρή τροποποίηση στο κείμενο που ελέγχεται (η οποία μπορεί να μεταβάλλει ελάχιστα το νόημά του) μπορεί να αλλάξει την αξιολόγηση που δίνουν αυτά τα εργαλεία.
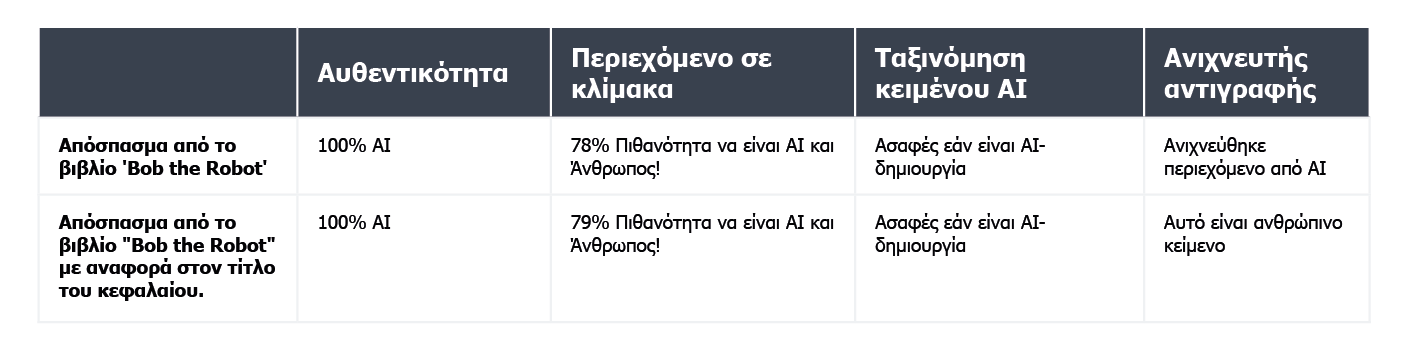
Πάρτε, για παράδειγμα, το παιδικό βιβλίο Bob the Robot, το οποίο δημιουργήθηκε κατά 80% από τεχνητή νοημοσύνη. Ο εκδότης απέδωσε το 20% της δημιουργίας σε ανθρώπινη επεξεργασία του κειμένου. Το τμήμα που επαληθεύσαμε όσον αφορά τον τρόπο δημιουργίας του βιβλίου ήταν το πρώτο του κεφάλαιο, που αποτελείται από 276 λέξεις. Ουσιαστικά επαληθεύσαμε το ίδιο κείμενο δύο φορές, με μια μόνο μικρή αλλαγή: προσθέσαμε την ένδειξη "Κεφάλαιο 1: Αστροπολιτεία" πριν από το περιεχόμενο του κεφαλαίου. Κατά συνέπεια, το Copyleaks.com άλλαξε εντελώς την εκτίμησή του για την προέλευση του βιβλίου. Στο καθαρό κείμενο του κεφαλαίου, το εργαλείο εντόπισε περιεχόμενο που δημιουργήθηκε από τεχνητή νοημοσύνη, αλλά το ίδιο κείμενο με πληροφορίες σχετικά με τον αριθμό και τον τίτλο του κεφαλαίου θεωρήθηκε ανθρώπινης γραφής.
Πώς ανταποκρίνονται λοιπόν οι ανιχνευτές στο μεταφρασμένο περιεχόμενο; Ως παράδειγμα, χρησιμοποιήσαμε περιεχόμενο γραμμένο από έναν κειμενογράφο χωρίς τη βοήθεια τεχνητής νοημοσύνης. Το άρθρο ήταν γραμμένο στα πολωνικά. Παρόλο που ορισμένα εργαλεία δεν υποστηρίζουν αυτή τη γλώσσα, εξακολουθούν να προσπαθούν να επαληθεύσουν το περιεχόμενό του χωρίς να επισημάνουν τυχόν σφάλματα. Τα αποτελέσματα που παρείχε το originality.ai έδειξαν 77% βεβαιότητα ότι το περιεχόμενο ήταν γραμμένο από άνθρωπο κατά την επαλήθευση του πολωνικού κειμένου. Το ίδιο κείμενο, όταν μεταφράστηκε χρησιμοποιώντας το DeepL, έδωσε στο εργαλείο μόνο 67% βεβαιότητα ότι ήταν γραμμένο από άνθρωπο. Η βεβαιότητα αυτή πέφτει στο 36% όταν το κείμενο μεταφράζεται από το Google Translate.
Είναι ενδιαφέρον ότι ένα άλλο εργαλείο, το Copyleaks, το οποίο υποστηρίζει επίσημα πολωνικό περιεχόμενο, ταξινόμησε σωστά όλες τις εκδόσεις. Η πιθανότητα ότι το μεγαλύτερο μέρος του κειμένου ήταν γραμμένο από άνθρωπο (λαμβάνοντας υπόψη ότι το εργαλείο αξιολογεί ξεχωριστά τα επιμέρους τμήματα του κειμένου) ήταν 99,9% για την πολωνική έκδοση, 89,8% για τη μετάφραση DeepL και 90,2% για την έκδοση του Google Translate. Αν και οι διαφορές είναι μικρές, είναι ενδιαφέρον ότι η μετάφραση της Google θεωρείται πιο κοντά σε ανθρώπινο στυλ γραφής από το DeepL, το οποίο κατατάχθηκε αντίθετα από την Originality.
Πώς διαφέρουν οι ανιχνευτές περιεχομένου AI από τους ανθρώπους;
Ερευνητές από τη Σχολή Μηχανικής και Εφαρμοσμένων Επιστημών του Πανεπιστημίου της Πενσυλβάνια διερεύνησαν τον τρόπο με τον οποίο οι άνθρωποι διακρίνουν το περιεχόμενο που δημιουργείται από τεχνητή νοημοσύνη. Είμαστε σε θέση να εντοπίσουμε τις διαφορές και ποιους παράγοντες λαμβάνουμε υπόψη στην κρίση μας;
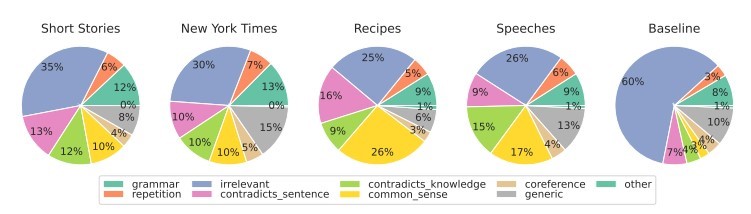
Για διάφορους τύπους περιεχομένου, εστιάζουμε κυρίως στη συνάφεια, η οποία συνήθως ασκεί την ισχυρότερη επιρροή στην αξιολόγησή μας. Στο πλαίσιο του περιεχομένου που παράγεται από τεχνητή νοημοσύνη, εντοπίζουμε επίσης σφάλματα που απορρέουν από την έλλειψη λογικής κοινής λογικής, την οποία τα εργαλεία τεχνητής νοημοσύνης δεν μπορούν να επαληθεύσουν, και την παρουσία αντιφατικών τμημάτων.
Οι ανιχνευτές τεχνητής νοημοσύνης βασίζουν τις εκτιμήσεις τους κυρίως στην προβλεψιμότητα και την τυχαιότητα του κειμένου, χωρίς να λαμβάνουν υπόψη πολλούς άλλους παράγοντες που επισημάνθηκαν από τους συμμετέχοντες στη μελέτη. Το θέσαμε σε δοκιμασία με ένα άρθρο που δημιουργήθηκε από τεχνητή νοημοσύνη τον Σεπτέμβριο του 2022, προτού γίνει γνωστό το ChatGPT. Το άρθρο είναι γεμάτο από υφολογικά λάθη, παράλογες προτάσεις και αδέξιες διατυπώσεις από τη μία πλευρά, αλλά από την άλλη είναι όντως "πρωτότυπο" και αξιοσημείωτα τυχαίο.
Το κείμενο ήταν αρχικά στα πολωνικά, οπότε επαναλάβαμε τη διαδικασία της αυτόματης μετάφρασης μέσω των DeepL και Google Translate, και για το καλό, εξετάσαμε και το αρχικό κείμενο (έχετε υπόψη σας, δεν υποστηρίζουν όλα τα εργαλεία την πολωνική γλώσσα, ωστόσο αναλαμβάνουν την αξιολόγησή της).
Ακολουθούν τα αποτελέσματα:
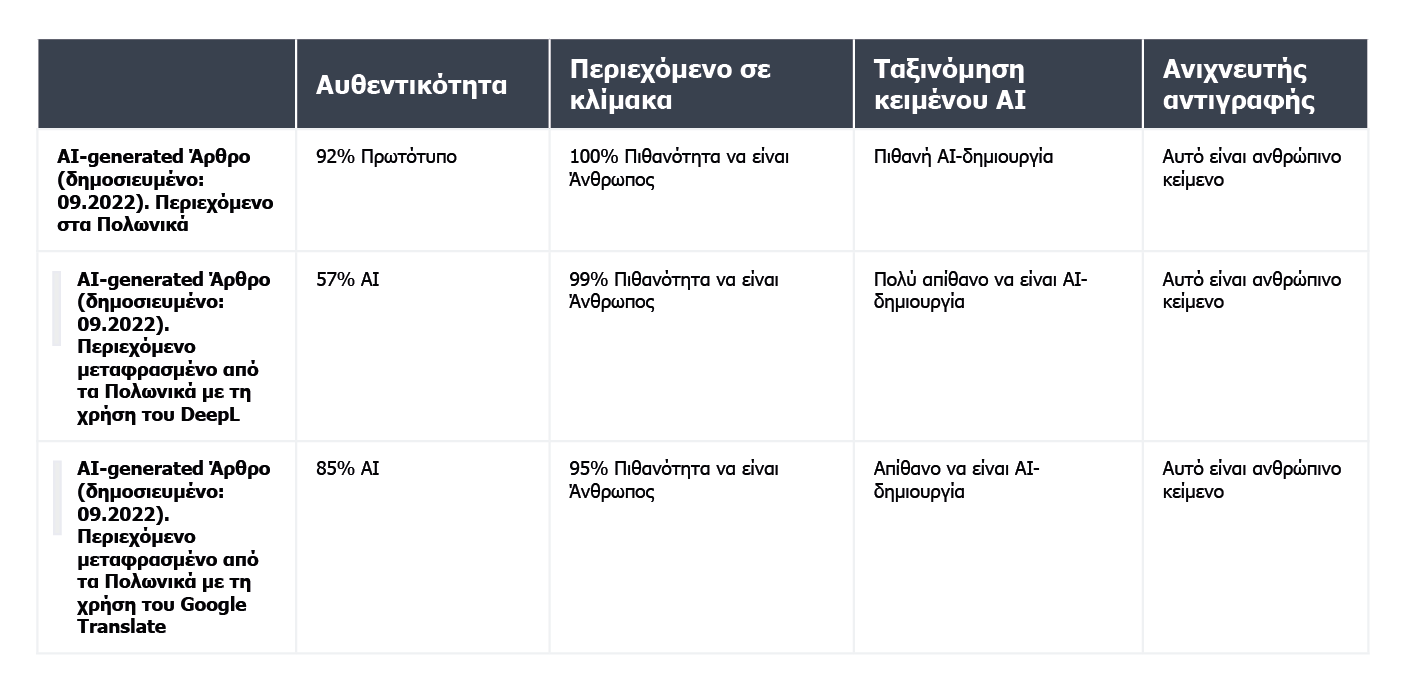
Όπως είναι προφανές, το Originality.ai κατάφερε να αξιολογήσει καλύτερα το μεταφρασμένο κείμενο, αλλά τα αποτελέσματά του δεν είναι μονοσήμαντα. Λάβετε υπόψη ότι η διαδικασία της αυτόματης μετάφρασης μπορεί να εισάγει ένα "αφύσικο" στοιχείο στο περιεχόμενο, το οποίο μπορεί εν μέρει να ευθύνεται για την αυξημένη πιθανότητα το περιεχόμενο να γίνει αντιληπτό ως παραγόμενο από τεχνητή νοημοσύνη.
Περίληψη
Το παράδοξο των εργαλείων ανίχνευσης περιεχομένου με τεχνητή νοημοσύνη είναι ότι έχουμε τέτοιο επίπεδο σκεπτικισμού σχετικά με την ποιότητα των κειμένων που παράγονται με τεχνητή νοημοσύνη, ώστε χρειαζόμαστε ένα άλλο εργαλείο βασισμένο στην τεχνητή νοημοσύνη για την ανίχνευσή τους. Τα κρίσιμα ερωτήματα που πρέπει να θέσουμε στον εαυτό μας σε αυτό το σημείο είναι τα εξής: Μπορούμε να προσδιορίσουμε με απόλυτη βεβαιότητα τον τρόπο με τον οποίο δημιουργήθηκε ένα κομμάτι περιεχομένου; Αν ένα άρθρο είναι καλογραμμένο και δεν περιέχει πραγματολογικά λάθη, έχει πραγματικά σημασία ο τρόπος που γράφτηκε;
Υπάρχει μια ευρέως διαδεδομένη πεποίθηση ότι το περιεχόμενο που έχει δημιουργηθεί από τεχνητή νοημοσύνη είναι χαμηλής ποιότητας. Ορισμένοι υποστηρίζουν επίσης ότι οι ιστότοποι θα "τιμωρούνται" για το περιεχόμενο που δημιουργείται με αυτόν τον τρόπο. Ωστόσο, η Bing και η Google κινούνται προς τη χρήση τεχνητής νοημοσύνης στις μηχανές αναζήτησης, γεγονός που υποδηλώνει ότι βλέπουν τα οφέλη τέτοιων λύσεων.
Κανένα από τα εργαλεία δεν είναι αλάνθαστο. Στη δοκιμή μας, ορισμένα τα κατάφεραν καλύτερα στην αξιολόγηση κειμένων γραμμένων από ανθρώπους, ενώ άλλα υπερείχαν με κείμενα γραμμένα από τεχνητή νοημοσύνη. Τα αποτελέσματα για κάποιο περιεχόμενο διέφεραν σημαντικά μεταξύ των εργαλείων. Κατά την επαλήθευση επιλεγμένων αποσπασμάτων, γνωρίζαμε πώς δημιουργήθηκαν, αλλά αν είχαμε πραγματοποιήσει μια τέτοια δοκιμή στα τυφλά, τα αποτελέσματα θα ήταν απλώς αναξιόπιστα. Το μεγαλύτερο πρόβλημα με τις αξιολογήσεις αυτών των εργαλείων είναι η αβεβαιότητα σχετικά με το πότε είναι σωστές και πότε λανθασμένες. Χρησιμοποιώντας τα, δεν ξέρουμε πραγματικά ποτέ αν μπορούμε να τα εμπιστευτούμε σε μια συγκεκριμένη περίπτωση.
Το παρακάτω άρθρο αποτελεί μετάφραση του πολωνικού άρθρου "Detektory treści AI - jak radzą sobie z klasyfikacją tekstu?" που έγραψε η Agata Gruszka, International SEO Manager της WhitePress®.


