Наскільки ефективно детектори ШІ-контенту можуть класифікувати тексти?
(2 хвилин читання)

Більшість інструментів, що генерують контент за допомогою ШІ, використовують мовні моделі GPT, розроблені фахівцями компанії OpenAI. Тому шаблони, які вони використовують для створення контенту, певною мірою схожі. Сьогодні ми можемо створювати, редагувати та покращувати тексти не лише безпосередньо в додатку ChatGPT, а й в документах notion.so або за допомогою плагіна Grammarly.
На сучасному етапі все більше контенту, опублікованого в інтернеті, генерується штучним інтелектом або за його допомогою. Відповідно, з’являються нові способи перевірки походження контенту, а саме — детектори ШІ-контенту. Ми вирішили дослідити їхню надійність та дізнатися, наскільки можна їм довіряти.
Як працюють детектори ШІ-контенту?
В основі інструментів для виявлення ШІ-контенту лежать нові мовні моделі, навчені розрізняти тексти, написані людиною та згенеровані штучним інтелектом. Ці інструменти дають ймовірнісні оцінки на основі передбачуваності тексту (perplexity) та його варіативності (burstiness). Варіативність визначає змінність передбачуваності. Люди зазвичай пишуть більш варіативно: наприклад, ми часто чергуємо довгі речення з короткими та простішими. Детектори ШІ-контенту розпізнають ці особливості, аналізуючи мільйони зразків текстів, які попередньо були класифіковані як написані людиною або створені штучним інтелектом.
ШІ-моделі на кшталт ChatGPT та інші інструменти на основі GPT можуть генерувати контент різними мовами, проте більшість інструментів для його перевірки підтримують насамперед англійську. Як у такому випадку перевіряти контент, написаний іншими мовами?
Одним із методів є перевірка текстів, автоматично перекладених інструментами на кшталт DeepL або Google Перекладач. Однак варто пам’ятати, що такий метод перекладу передбачає використання певних шаблонів, за якими відбувається автоматичний переклад текстів, а це впливає на оцінку, виконану детектором. Утім, деякі детектори все ж перевіряють контент іншими мовами, попри те, що офіційно вони підтримують лише англійську.
Крім того, кожен детектор має власні обмеження щодо обсягу контенту, який він може перевірити. Цей обсяг залежить від того, чи це безкоштовна, чи платна версія програми. До того ж кожен із них по-різному оцінює походження контенту: одні надають відсоток упевненості в тому, що текст (на їхню думку) згенерований ШІ або написаний людиною, інші використовують вербальні оцінки або бінарну шкалу — «так» або «ні».
Інструменти, які ми перевірили
З-поміж доступних на ринку рішень ми вибрали чотири найпопулярніші інструменти та детально перевірили їх, використавши 20 вибраних текстів-прикладів. Ми вибрали 10 текстів, написаних людьми, і 10 текстів, згенерованих штучним інтелектом, щоб оцінити, як ці інструменти їх класифікують.
До групи текстів, створених традиційним способом, ми включили статті, повністю написані копірайтерами (деякі з них були написані до 2021 року, що виключає можливість використання ШІ для їхнього створення), уривки з літературних творів (зокрема дитячих книжок), новинні статті та користувальницькі інструкції. Контент, створений штучним інтелектом, включав фрагменти літературних творів, створених таким способом — «Внутрішній світ ШІ: мемуари ChatGPT» (The Inner Life of an AI: A Memoir by ChatGPT) та «Робот Боб» (Bob the Robot), а також статті, створені за допомогою штучного інтелекту (як ті, що вже були опубліковані в інтернеті, так і «свіжостворені» за допомогою GPT-3.5 і GPT-4). Також до нашої вибірки контенту для аналізу увійшли тексти польською мовою та їхні переклади від DeepL та Google Перекладача. Усі тести проводилися на одних і тих же уривках текстів, а результати, зважаючи на різні методи класифікації, були проаналізовані на рівні окремих інструментів.
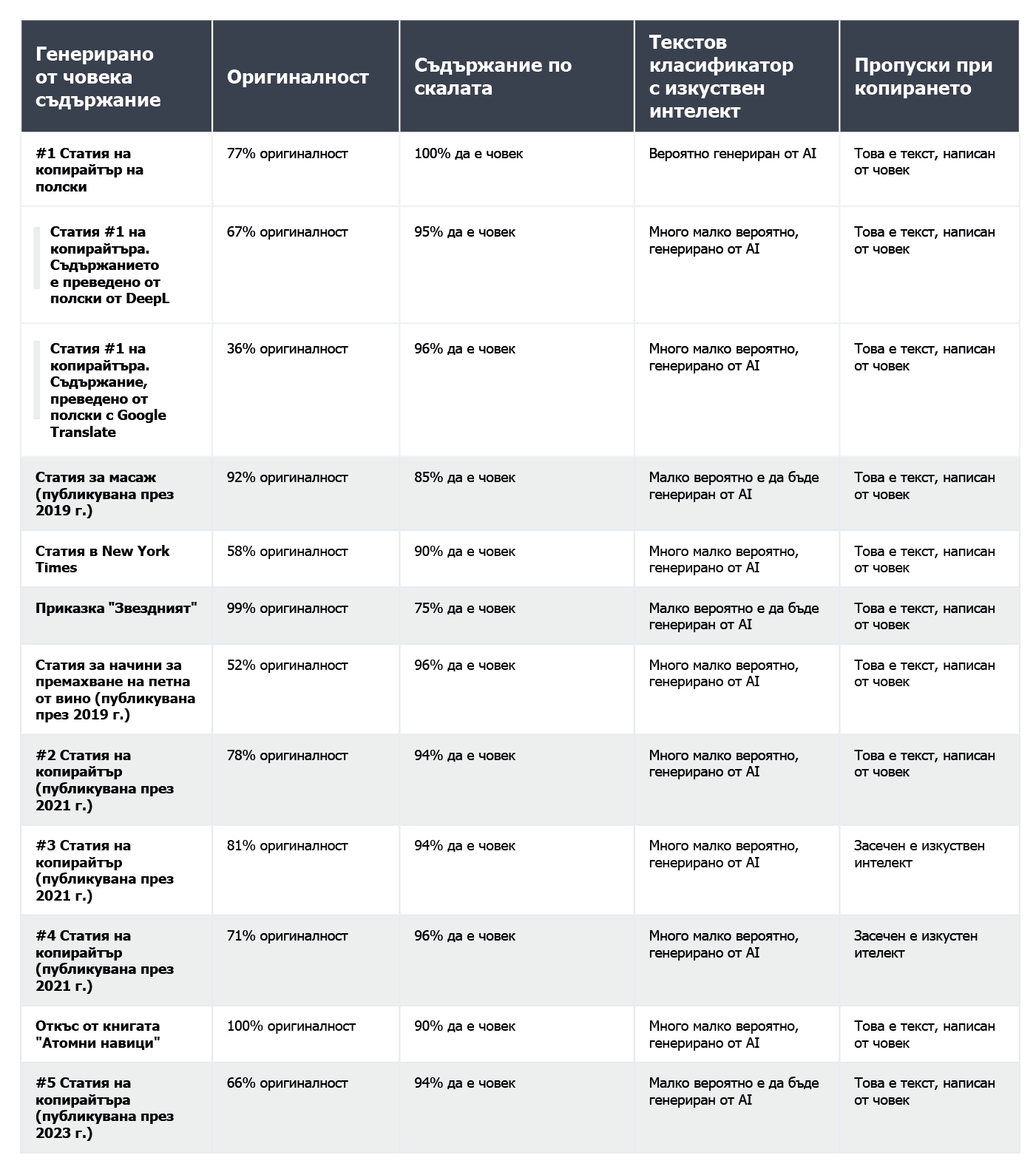
Нижче представлені результати оцінки текстів, написаних людьми:
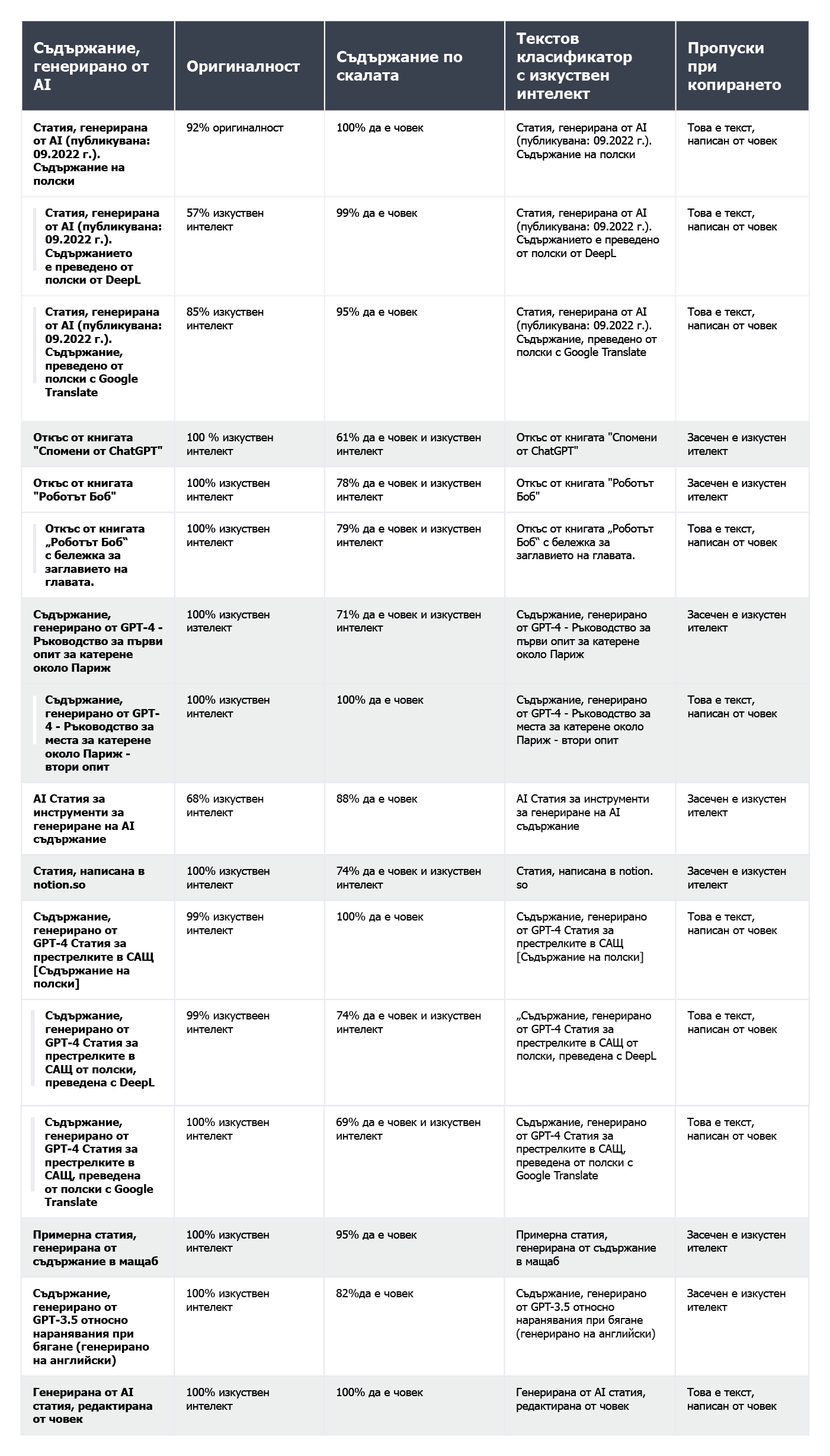
а також текстів, згенерованих штучним інтелектом:
AI Text Classifier від OpenAI
AI Text Classifier від творців моделей GPT з компанії OpenAI — це найпопулярніший інструмент для виявлення контенту, створеного штучним інтелектом. Він здійснює оцінку та формулює свої висновки з погляду ймовірності того, що проаналізований текст був створений штучним інтелектом. Для цього використовується низка категорій: «дуже малоймовірно, що згенеровано ШІ», «малоймовірно, що згенеровано ШІ», «незрозуміло, чи згенеровано ШІ», «можливо, згенеровано ШІ» і «ймовірно, згенеровано ШІ». Як бачимо, у цій шкалі досить багато нюансів. В описі свого інструмента розробники з OpenAI зазначають, що не завжди результати можуть бути точними, і що детектор потенційно може неправильно класифікувати обидва види контенту. Важливо зазначити, що модель, яка використовувалася для навчання детектора AI Text Classifier, не містила студентських та учнівських робіт, тому його не рекомендується використовувати для перевірки такого контенту.
З 10 текстів, написаних людиною, AI Text Classifier правильно класифікував дев’ять, вказавши, що «дуже малоймовірно» або «малоймовірно», що вони були згенеровані ШІ. Однак класифікація текстів, створених ШІ, йому дається важче. У цьому випадку інструмент часто визначає, що «незрозуміло», «малоймовірно» або «можливо», що текст згенерований ШІ.
Originality.AI
Ще один популярний інструмент для перевірки контенту, створеного за допомогою ШІ — це Originality. Розробники стверджують, що його ефективність становить 95,93%. Це єдиний платний інструмент у нашому списку, який стягує плату в розмірі $0,01 за кожні 100 перевірених слів. Ціна мінімального пакета — $20. Originality не лише встановлює походження контенту, а й перевіряє його на наявність плагіату.
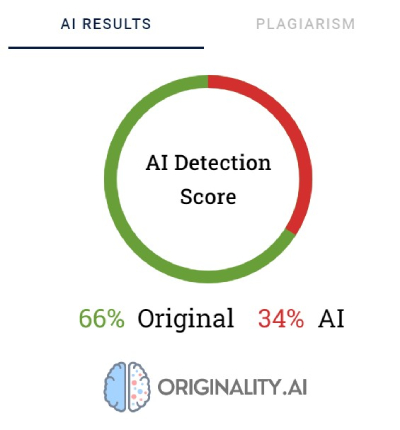
Originality використовує відсотковий показник для відображення ступеня впевненості у тому, що контент був створений людиною або ШІ. Оцінка «66% Оригінальний» означає не те, що 66% тексту написала людина, а 34% — штучний інтелект, а те, що детектор на 66% впевнений у тому, що контент був створений людиною. Інструмент виділяє червоним кольором ті частини, які, на його думку, були згенеровані ШІ, а зеленим — ті, щодо яких він упевнений, що це робота людини. Цікаво, що в текстах, які в кінцевому підсумку класифікуються як написані людиною, більша частина або принаймні половина контенту виділяється червоним кольором.
Іноді Originality має труднощі з однозначною класифікацією контенту, написаного людиною. З усіх перевірених фрагментів лише один був класифікований як написаний людиною зі 100% упевненістю. У випадку решти текстів результати коливалися в межах 52–92% упевненості в тому, що вони були написані людиною.
Дещо краще інструмент впорався з перевіркою контенту, згенерованого ШІ: для 7 з 10 текстів упевненість у тому, що контент був згенерований ШІ, становила 100% або 99%. Сумніви виникали під час перевірки ШІ-контенту, створеного польською мовою, а потім перекладеного англійською. Попри те, що стаття була створена однією зі старіших моделей GPT (і була опублікована в блозі ще у вересні 2022 року) і містила чимало стилістичних помилок, Originality був на 92% упевнений в тому, що польський текст був написаний людиною. Але під час аналізу перекладу співвідношення змінилося на користь ШІ: інструмент був на 57% упевнений, що контент, перекладений у DeepL, був створений ШІ, а у випадку перекладу з Google Перекладача — на 85%.
Проте найбільше проблем в Originality викликала стаття з популярного сайту bankrate.com, на якому публікується контент, згенерований ШІ та перевірений людьми. Це був єдиний випадок, коли інструмент був на 88% упевнений, що статтю написала людина, хоча насправді вона була створена за допомогою ШІ. Схоже, що Originality можна «обманути» шляхом ретельного редагування тексту.
Copyleaks
Оцінка контенту в Copyleaks базується на бінарній шкалі: можливі результати — «цей текст написаний людиною» і «виявлено ШІ-контент». Навівши курсор миші на текст, можна переглянути деталі перевірки конкретних сегментів. Інструмент покаже ймовірність того, що вибраний фрагмент тексту був написаний людиною або ШІ.
У 2 із 10 текстів, написаних людиною, Copyleaks виявив контент, створений ШІ. Що ж стосується текстів, створених ШІ, то інструмент приблизно з однаковою ймовірністю оцінив їх як такі, що були створені людиною та ШІ. Тому результати не є надійними й навіть можуть вважатися безкорисними. Утім, вражає те, наскільки Copyleaks «чутливий» до змін. Зміна запиту (промпту) в чаті або додавання номера розділу та заголовка в текст, що перевірявся, призводили до повної зміни результатів оцінювання.
Content at Scale — AI DETECTOR
Content at Scale — це насамперед інструмент для автоматичної генерації контенту, натомість функція перевірки є додатковою. Розробники інструменту стверджують, що тексти, згенеровані їхньою системою, неможливо виявити за допомогою детекторів ШІ. У зв’язку з цим виникає питання: чи був цей детектор розроблений для підтвердження ефективності роботи генератора?
На сайті компанії міститься приклад тексту, згенерованого за допомогою Content at Scale. Їхній власний детектор оцінив з 95% ймовірністю, що цей текст був написаний людиною. Водночас AI Text Classifier визначив, що «малоймовірно», що це робота штучного інтелекту. Натомість перехитрити Originality і Copyleaks було не так легко. Originality оцінив текст як «100% ШІ», а Copyleaks «виявив ШІ-контент». Як бачимо, різні детектори пропонують різні підходи.
Детектор Content at Scale доволі вдало розпізнав контент, написаний людиною. Для 9 з 10 перевірених уривків ймовірність того, що вони були написані людиною, перевищила 90%.
Однак із ШІ-контентом було складніше: 6 із 10 текстів детектор оцінив як такі, що були створені як людиною, так і ШІ. Решта текстів були помилково класифіковані як написані людиною.
Обманути детектори
ШІ-контент не з’являється нізвідки. За інструкціями (промптами), за якими він створюється, завжди стоїть людина. Тож виникає питання: чи існують способи обманути детектори ШІ-контенту та створити контент, який неможливо виявити?
В інтернеті описано безліч різних способів створити відповідні промпти. Один із них полягає в тому, щоб пояснити чат-боту згадані вище поняття «передбачуваності» та «варіативності». Ідея полягає в тому, щоб навчити ШІ враховувати ці фактори під час генерації нового тексту. Щоб перевірити цей спосіб, ми доручили чат-боту на базі моделі GPT-4 написати статтю про найкращі місця для скелелазіння поблизу Парижа.
Результати виявилися цікавими. Ось результати перевірки першої версії тексту та другої версії, перед створенням якої ми пояснили чат-боту критерії оцінювання та підказали йому, як зробити контент більш схожим на той, який створює людина:
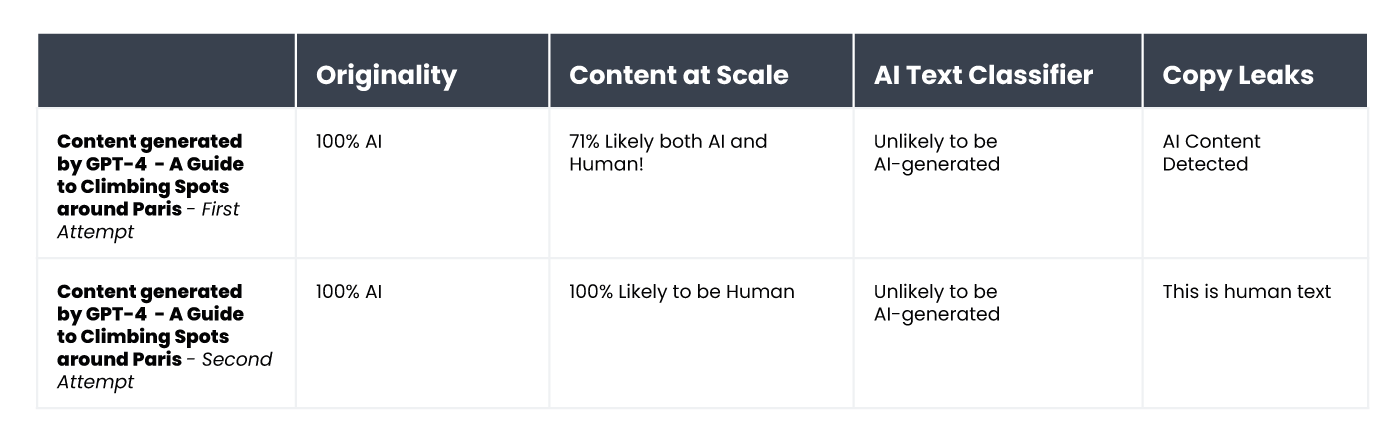
Єдиним інструментом, який не вдалося обманути, був Originality. В обох випадках нам вдалося перехитрити AI Text Classifier, який встановив, що ймовірність того, що обидва тексти були згенеровані ШІ, є низькою. Цікаво, що Content at Scale та Copyleaks змінили свою оцінку після того, як ChatGPT-4 створив текст з урахуванням рекомендацій щодо передбачуваності та варіативності.
Що робить детектори ненадійними?
Детектори націлені на пошук передбачуваних елементів контенту, тобто — на передбачуваність (perplexity). Що нижча передбачуваність, то вища ймовірність того, що текст був створений традиційним способом — написаний людиною. Проте так само як незначні зміни в промптах, введених у ChatGPT, можуть забезпечити зовсім інший результат, так і незначна зміна в тексті, що перевіряється (яка зовсім трохи змінює його зміст), може вплинути на оцінку, дану цими інструментами.
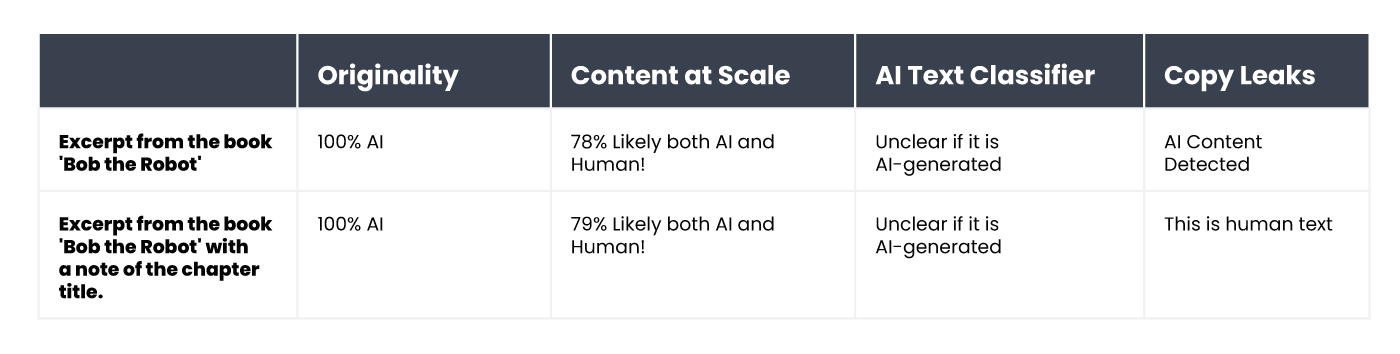
Розгляньмо, наприклад, дитячу книжку «Робот Боб» (Bob the Robot), яка на 80% була створена штучним інтелектом. 20% роботи над книгою (редагування тексту) вважається роботою людини. Уривок, який ми перевіряли в контексті способу створення книги — це її перший розділ, що складається з 276 слів. Фактично ми перевірили один і той самий текст двічі, але з невеликою зміною: під час другої спроби перед текстом самого розділу ми дописали «Розділ 1: Зоряне місто» («Chapter 1: Star City»). Після цього детектор Copyleaks повністю змінив свою оцінку авторства книги. У чистому тексті розділу інструмент виявив ШІ-контент, однак той самий текст, але з інформацією про номер і назву розділу, був оцінений як написаний людиною. Утім, скільки детекторів, стільки й оцінок. Незмінними залишилися лише оцінки Originality та AI Text Classifier. Перший інструмент висловив 100% упевненості в тому, що обидва варіанти були створені ШІ, а другий зазначив, що незрозуміло, чи були тексти створені ШІ. Натомість Content at Scale присвоїв такі самі оцінки з мінімальною різницею у відсотках.
А як детектори реагують на перекладений контент? Для прикладу ми взяли матеріал, написаний копірайтером без допомоги ШІ. Стаття була написана польською мовою. Попри те, що деякі інструменти не підтримують польську мову, вони все одно намагаються перевірити зміст статті, не помічаючи помилок.
Результати перевірки польського тексту, надані детектором Originality, свідчили про 77% упевненості в тому, що контент був написаний людиною. Той самий текст, перекладений за допомогою DeepL, дозволив інструменту висловити лише 67% упевненості в тому, що його написала людина, а після перевірки тексту, перекладеного за допомогою Google Перекладача, цей показник знизився до 36%.
Цікаво, що Copyleaks — детектор, який офіційно підтримує польську мову — правильно класифікував усі версії. Згідно з його оцінкою, ймовірність того, що більша частина тексту була написана людиною (пам’ятаймо, що інструмент оцінює кожну частину тексту окремо), становила 99,9% для польської версії, 89,8% — для перекладу з DeepL, і 90,2% — для перекладу з Google Перекладача. Інтригує той факт, що переклад Google був визнаний більш схожим на людський стиль письма, ніж переклад DeepL, який від Originality отримав протилежну оцінку (хоча відмінності незначні).
Чим детектори ШІ-контенту відрізняються від людей?
Дослідники зі Школи інженерії та прикладних наук Пенсільванського університету вивчали, як люди розпізнають контент, створений ШІ. Чи здатні ми помітити відмінності, і які фактори враховуємо під час оцінювання?
Джерело: https://
Перевіряючи різні типи контенту, ми насамперед зосереджуємося на релевантності, яка зазвичай найбільше впливає на нашу оцінку. У контенті, згенерованому штучним інтелектом, ми також виявляємо помилки, пов’язані з порушенням загальної логіки, яку ШІ-інструменти не можуть перевірити, а також наявність суперечливих фрагментів.
Оцінки детекторів ШІ в основному базуються на передбачуваності та варіативності тексту, проте вони не враховують багато інших факторів, на які вказували учасники дослідження. Ми перевірили це на прикладі статті, створеної штучним інтелектом у вересні 2022 року — ще до того, як ChatGPT став загальновідомим. З одного боку, в статті є багато стилістичних помилок, нелогічних речень та дивних формулювань, але з іншого боку, вона дійсно «оригінальна» і, безумовно, варіативна.
Оригінальний текст писався польською мовою, тому ми повторили процедуру автоматичного перекладу в DeepL та Google Перекладачі, а заради цікавості перевірили ще й оригінальний текст (пам’ятаймо, що не всі інструменти підтримують польську мову, але все одно оцінюють текст).
Ось які результати ми отримали:
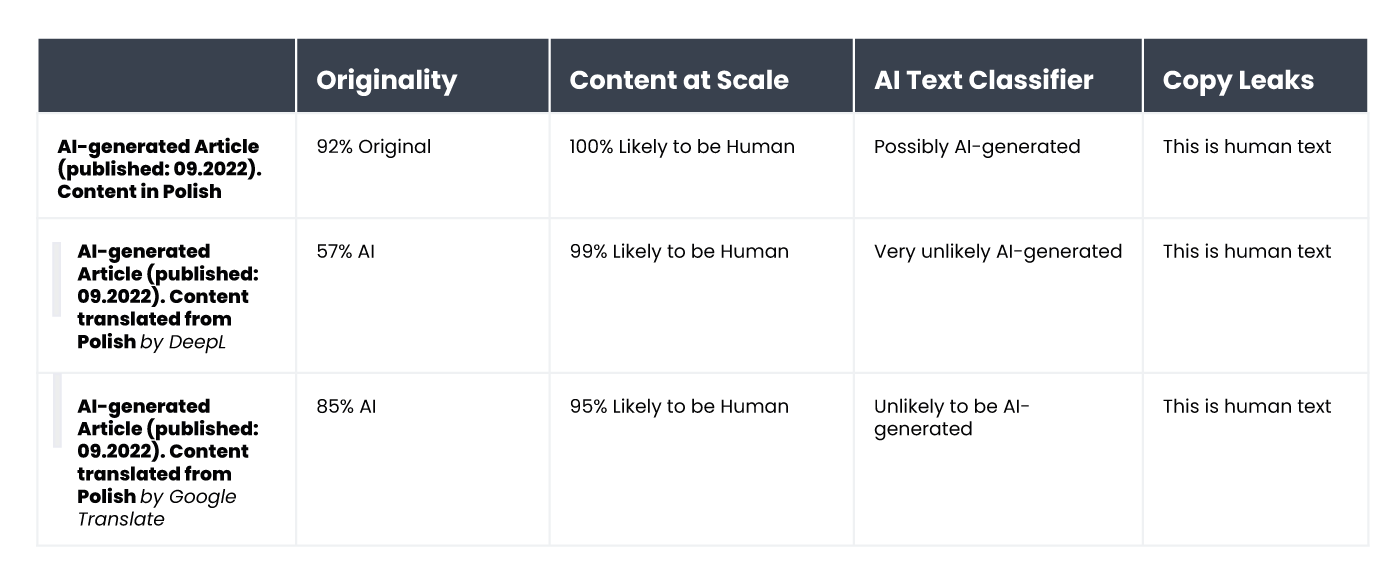
Як бачимо, найкраще з оцінюванням перекладеного тексту впорався Originality.ai, проте і його результати неоднозначні. Варто пригадати, що під час автоматичного перекладу в тексті можуть з’являтися «неприродні» елементи, що може частково пояснювати підвищену ймовірність того, що контент сприймається як згенерований ШІ.
Висновок
Парадокс інструментів для виявлення ШІ-контенту полягає в тому, що ми настільки скептично ставимося до якості текстів, згенерованих ШІ, що нам потрібен ще один ШІ-інструмент для їхнього виявлення. На цьому етапі ми повинні поставити собі декілька важливих запитань. Чи можемо ми самі абсолютно точно визначити, яким способом було створено той чи інший контент? І якщо стаття написана добре і не містить фактичних помилок, чи має значення те, яким способом вона написана?
Багато хто вважає, що контент, створений ШІ, має низьку якість. Дехто також стверджує, що сайти отримуватимуть «покарання» за контент, створений таким способом. Однак Bing та Google просуваються в напрямку використання штучного інтелекту у своїх пошукових системах, що свідчить про те, що вони усвідомлюють переваги таких рішень.
Жоден з інструментів не є досконалим. У нашому дослідженні деякі з них показали кращі результати під час оцінювання текстів, написаних людиною, тоді як інші краще оцінювали тексти, написані ШІ. У деяких випадках результати різних інструментів суттєво відрізнялися. Перевіряючи вибрані уривки текстів, ми знали, як вони були створені, проте якби ми проводили такий тест «наосліп», результати були б просто недостовірними. Найбільша проблема з оцінкою цих інструментів полягає в неможливості бути впевненими в тому, коли вони оцінюють контент правильно, а коли помиляються. Використовуючи їх, ми насправді ніколи не знаємо, чи можемо їм довіряти в тому або іншому випадку.
Ця стаття є перекладом статті польською мовою «Detektory treści AI - jak radzą sobie z klasyfikacją tekstu?» (авторка — Агата Грушка, International SEO Manager в компанії WhitePress®).


